数据分析的第一步是获取数据。本章将介绍如何从 Global Macro Data 获取全球宏观经济数据。该数据库涵盖了 243 个国家和地区的 46 个宏观经济变量,包括投资占GDP比重(inv_GDP)、出口占GDP 比重(exports_GDP)、政府支出占 GDP 比重(govexp_GDP)等。 有关该数据库的详细介绍参见:GMD:最新全球宏观数据库-243个国家46个宏观变量。
import pandas as pdimport osos.chdir(r"D:\Github\dslian\body") # 修改为你的工作路径# 获取数据并加载到 DataFrame''' 9M 左右,下载需要 10-15 秒url = "https://www.globalmacrodata.com/GMD.csv"data = pd.read_csv(url)# 保存数据到 data 文件夹下data.to_csv("data/GMD.csv", index=False)'''# 从 data 文件夹读取数据data = pd.read_csv("data/GMD.csv")# 查看前几行数据print(data.head())print(data.columns)
countryname ISO3 year nGDP rGDP rGDP_pc rGDP_USD deflator cons \
0 Aruba ABW 1950 NaN NaN NaN NaN NaN NaN
1 Aruba ABW 1951 NaN NaN NaN NaN NaN NaN
2 Aruba ABW 1952 NaN NaN NaN NaN NaN NaN
3 Aruba ABW 1953 NaN NaN NaN NaN NaN NaN
4 Aruba ABW 1954 NaN NaN NaN NaN NaN NaN
rcons ... ltrate cbrate M0 M1 M2 M3 M4 SovDebtCrisis \
0 NaN ... NaN NaN NaN NaN NaN NaN NaN NaN
1 NaN ... NaN NaN NaN NaN NaN NaN NaN NaN
2 NaN ... NaN NaN NaN NaN NaN NaN NaN NaN
3 NaN ... NaN NaN NaN NaN NaN NaN NaN NaN
4 NaN ... NaN NaN NaN NaN NaN NaN NaN NaN
CurrencyCrisis BankingCrisis
0 NaN NaN
1 NaN NaN
2 NaN NaN
3 NaN NaN
4 NaN NaN
[5 rows x 49 columns]
Index(['countryname', 'ISO3', 'year', 'nGDP', 'rGDP', 'rGDP_pc', 'rGDP_USD',
'deflator', 'cons', 'rcons', 'cons_GDP', 'inv', 'inv_GDP', 'finv',
'finv_GDP', 'exports', 'exports_GDP', 'imports', 'imports_GDP', 'CA',
'CA_GDP', 'USDfx', 'REER', 'govexp', 'govexp_GDP', 'govrev',
'govrev_GDP', 'govtax', 'govtax_GDP', 'govdef', 'govdef_GDP', 'govdebt',
'govdebt_GDP', 'HPI', 'CPI', 'infl', 'pop', 'unemp', 'strate', 'ltrate',
'cbrate', 'M0', 'M1', 'M2', 'M3', 'M4', 'SovDebtCrisis',
'CurrencyCrisis', 'BankingCrisis'],
dtype='object')
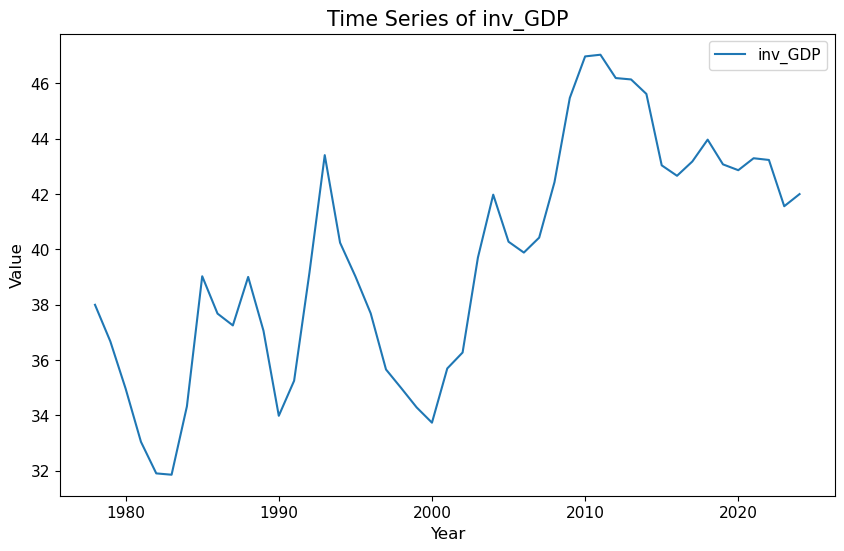
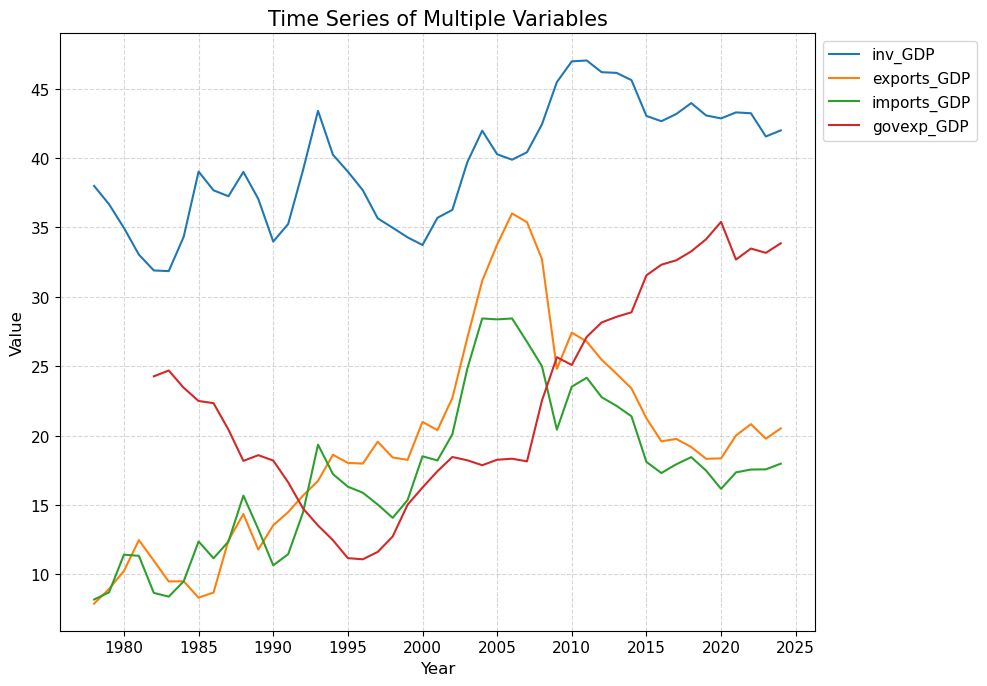
import matplotlib.pyplot as plt# 选择变量列表和国家vlist = ["inv_GDP", "exports_GDP", "imports_GDP", "govexp_GDP"]cname ="CHN"# 筛选出指定国家的数据china_data = data[data["ISO3"] == cname]# 选择样本范围china_data = china_data[(china_data["year"] >=1978) & (china_data["year"] <=2024)]# 绘制简单的时序图plt.figure(figsize=(10, 6))plt.plot(china_data["year"], china_data["inv_GDP"], label="inv_GDP")plt.xlabel("Year")plt.ylabel("Value")plt.title("Time Series of inv_GDP")plt.legend()plt.grid()plt.show()# 绘制多变量时序图plt.figure(figsize=(10, 7))for var in vlist: plt.plot(china_data["year"], china_data[var], label=var)plt.xlabel("Year")plt.ylabel("Value")plt.title("Time Series of Multiple Variables")plt.xticks(range(1980, 2026, 5))plt.legend(loc="upper left", bbox_to_anchor=(1, 1), ncol=1)plt.tight_layout()plt.show()