# 1. 读取并检查文件
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.ticker import FuncFormatter
import re
from IPython.display import display, HTML
# 设置中文字体
# 方案1:使用苹果系统自带的中文字体
plt.rcParams['font.sans-serif'] = ['PingFang HK']
# 方案2:使用其他常见中文字体
plt.rcParams['font.sans-serif'] = ['Heiti TC'] # 或者 'STHeiti'
# 辅助函数:按指定长度自动换行
def wrap_text(text, max_len=10):
"""将文本按指定长度自动换行"""
if not isinstance(text, str):
text = str(text)
wrapped = []
while text:
wrapped.append(text[:max_len])
text = text[max_len:]
return '<br>'.join(wrapped)
# 辅助函数:美化表格显示(纯文本样式)
def display_table(df, columns, max_widths, title=None):
"""使用HTML格式化显示表格(纯文本样式)"""
# 创建表头
headers = []
for col in columns:
wrapped_header = wrap_text(col, max_len=10)
headers.append(f'<th style="text-align:left; padding:5px; border-bottom:1px solid #000;">{wrapped_header}</th>')
# 创建表格行
rows = []
for _, row in df.iterrows():
row_cells = []
for col in columns:
# 获取列对应的原始数据
value = row[col] if col in row else ''
# 根据列设置最大宽度
max_width = max_widths.get(col, 10)
# 处理数值类型,保留两位小数
if isinstance(value, (int, float)):
value_str = f"{value:.2f}" if isinstance(value, float) else str(value)
else:
value_str = str(value)
# 自动换行
wrapped_value = wrap_text(value_str, max_len=max_width)
row_cells.append(f'<td style="text-align:left; padding:5px; border-bottom:1px solid #eee;">{wrapped_value}</td>')
rows.append(f'<tr>{"".join(row_cells)}</tr>')
# 构建完整HTML表格
table_html = f'''
<div style="margin:15px 0;">
{f'<h4>{title}</h4>' if title else ''}
<table style="border-collapse:collapse; width:100%;">
<thead>
<tr>{"".join(headers)}</tr>
</thead>
<tbody>
{"".join(rows)}
</tbody>
</table>
</div>
'''
# 显示表格
display(HTML(table_html))
# 读取数据
try:
df = pd.read_excel('data_clean/python_books_clean.xlsx')
print("数据读取成功,共有", len(df), "条记录")
# 显示数据集行数和列数
rows, columns = df.shape
if rows == 0:
print("错误:数据集中没有记录!")
else:
# 显示数据集行数和列数
print(f"数据包含 {rows} 行,{columns} 列")
# 检查数据列名
expected_columns = ['title', 'author', 'year', 'publisher', 'review_count', 'original_price', 'discounted_price', '页面排名']
missing_columns = [col for col in expected_columns if col not in df.columns]
if missing_columns:
print("\n警告:数据缺少以下列:", ', '.join(missing_columns))
print("请确保使用正确的列名:", ', '.join(expected_columns))
# 数据预处理
print("\n开始数据预处理...")
# 复制数据(使用深拷贝避免链式赋值警告)
df_processed = df.copy(deep=True)
# 将列名转为小写
df_processed.columns = df_processed.columns.str.strip().str.lower()
# 处理缺失值
missing_values = df_processed.isnull().sum()
if missing_values.sum() > 0:
print("\n处理缺失值:")
print(missing_values[missing_values > 0])
# 根据数据类型填充缺失值
for col in df_processed.columns:
if df_processed[col].dtype == 'object':
df_processed[col] = df_processed[col].fillna('未知')
else:
df_processed[col] = df_processed[col].fillna(df_processed[col].median())
# 处理异常值
if 'original_price' in df_processed.columns and 'discounted_price' in df_processed.columns:
# 确保价格非负
df_processed = df_processed[(df_processed['original_price'] >= 0) &
(df_processed['discounted_price'] >= 0)]
# 确保折扣价不高于原价
df_processed = df_processed[df_processed['discounted_price'] <= df_processed['original_price']]
# 计算折扣率
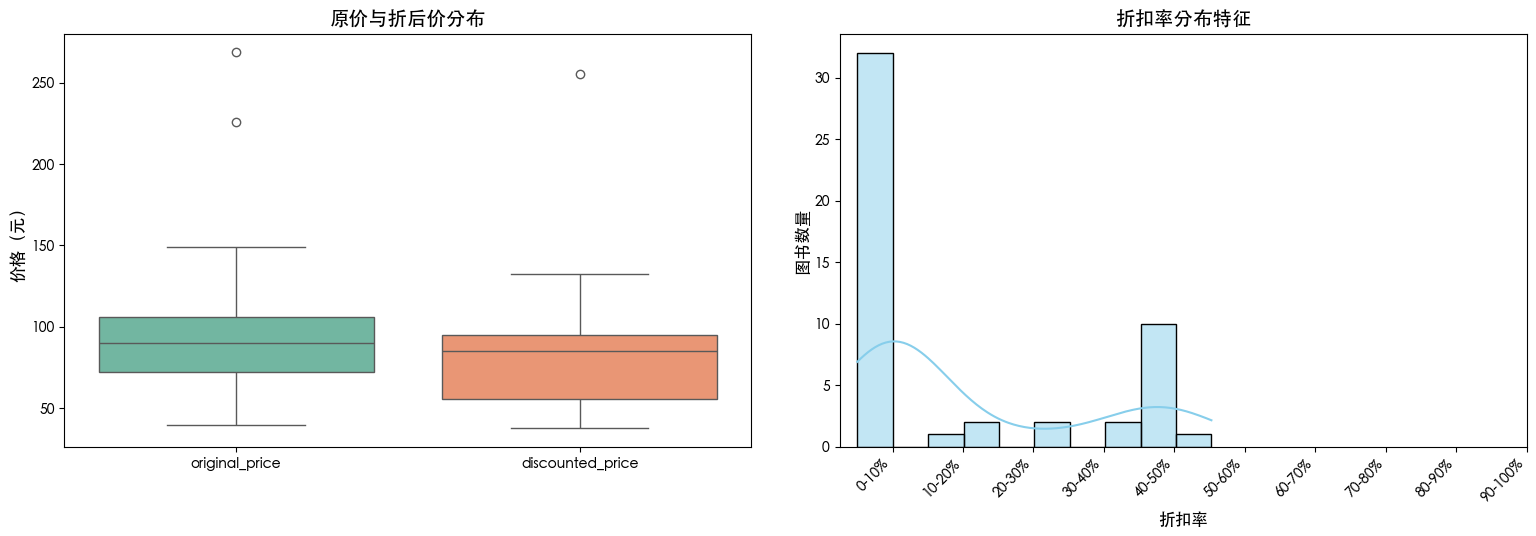
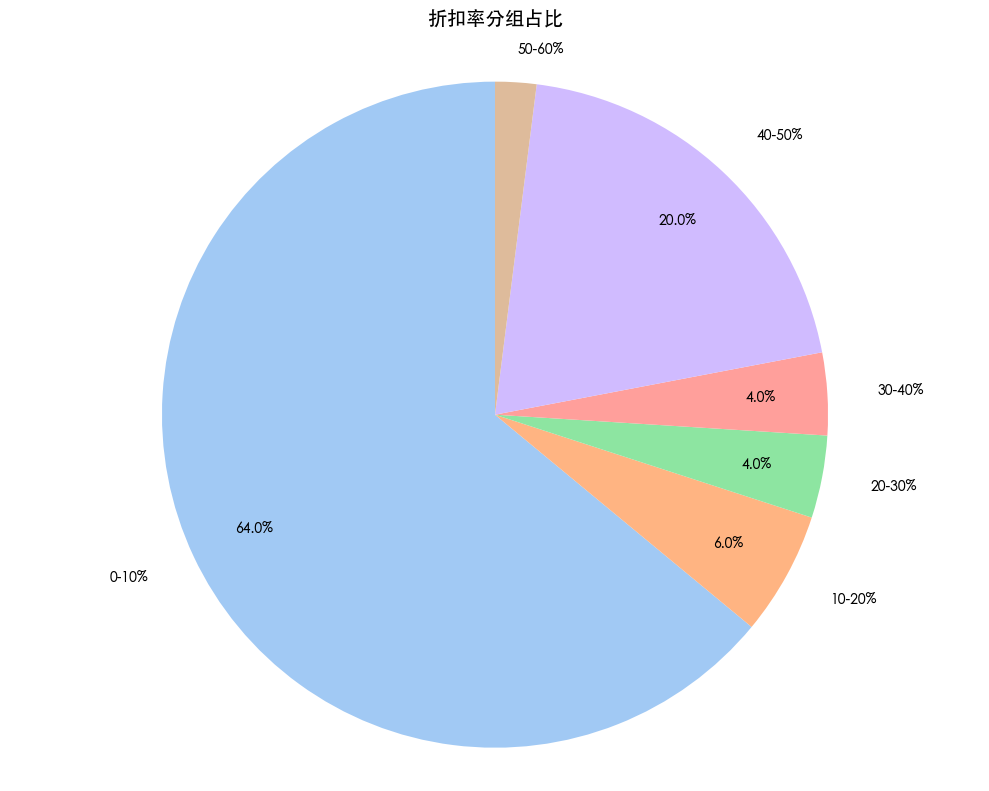
df_processed['discount_rate'] = 1 - df_processed['discounted_price'] / df_processed['original_price']
# 移除折扣率异常值
df_processed = df_processed[(df_processed['discount_rate'] >= 0) & (df_processed['discount_rate'] <= 1)]
if 'review_count' in df_processed.columns:
# 确保评论数非负
df_processed = df_processed[df_processed['review_count'] >= 0]
if 'year' in df_processed.columns:
# 处理年份异常值
current_year = pd.Timestamp.now().year
df_processed = df_processed[(df_processed['year'] >= 2000) & (df_processed['year'] <= current_year)]
print(f"数据预处理完成,剩余 {len(df_processed)} 条有效记录")
# 显示数据基本信息
print("\n数据基本信息:")
df.info()
# 显示数据前几行
print("\n数据前几行内容信息:")
head_df = df_processed.head()
# 定义列和最大宽度
columns = head_df.columns.tolist()
max_widths = {col: 10 for col in columns}
# 显示表格
display_table(head_df, columns, max_widths)
except FileNotFoundError:
print("错误:找不到数据文件!请确保data_clean文件夹中的python_books_clean.xlsx文件存在。")
except Exception as e:
print(f"错误:发生了一个未知错误: {e}")
df_processed = None数据读取成功,共有 50 条记录
数据包含 50 行,8 列
开始数据预处理...
处理缺失值:
year 12
original_price 3
discounted_price 1
dtype: int64
数据预处理完成,剩余 50 条有效记录
数据基本信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 50 entries, 0 to 49
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 title 50 non-null object
1 author 50 non-null object
2 year 38 non-null float64
3 publisher 50 non-null object
4 review_count 50 non-null int64
5 original_price 47 non-null float64
6 discounted_price 49 non-null float64
7 页面排名 50 non-null int64
dtypes: float64(3), int64(2), object(3)
memory usage: 3.3+ KB
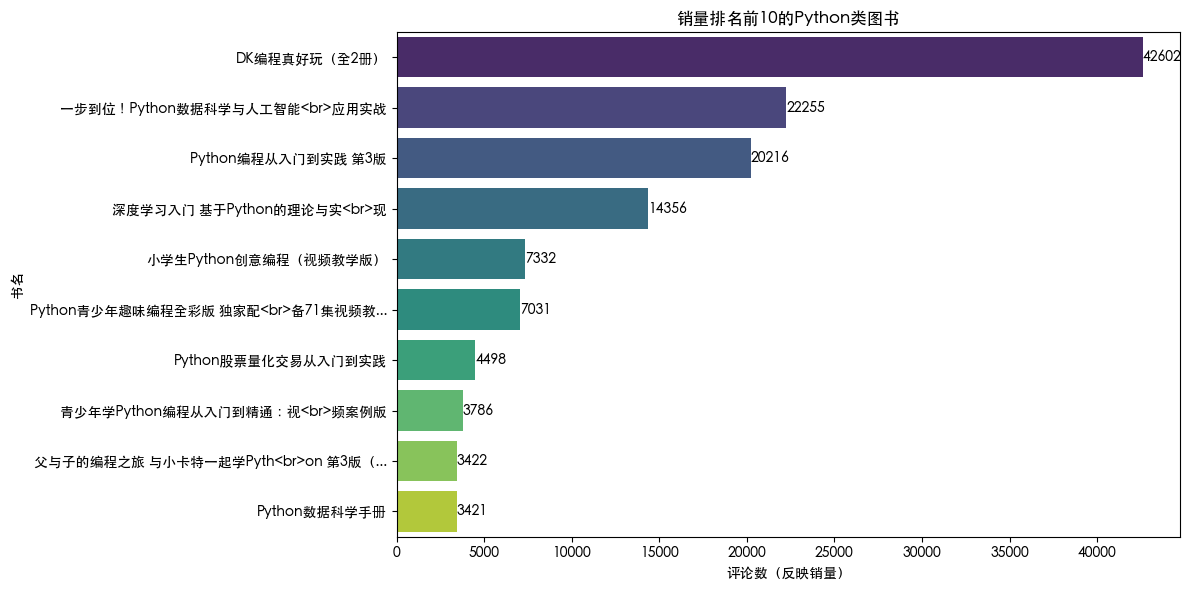
数据前几行内容信息:| title | author | year | publisher | review_cou nt |
original_p rice |
discounted _price |
页面排名 | discount_r ate |
|---|---|---|---|---|---|---|---|---|
| 小学生Python创 意编程(视频教学版) |
刘凤飞 | 2024.00 | 清华大学出版社 | 7332 | 89.00 | 84.60 | 1 | 0.05 |
| Python编程从入 门到实践 第3版 |
埃里克·马瑟斯 | 2023.00 | 人民邮电出版社 | 20216 | 109.80 | 69.80 | 2 | 0.36 |
| Python股票量化 交易从入门到实践 |
袁霄 | 2021.00 | 人民邮电出版社 | 4498 | 99.80 | 94.80 | 3 | 0.05 |
| Python从入门到 精通(第3版) |
明日科技 | 2023.00 | 清华大学出版社 | 2438 | 89.80 | 85.30 | 4 | 0.05 |
| 深度学习入门 基于P ython的理论与实 现 |
斋藤康毅 | 2021.00 | 人民邮电出版社 | 14356 | 69.80 | 39.80 | 5 | 0.43 |