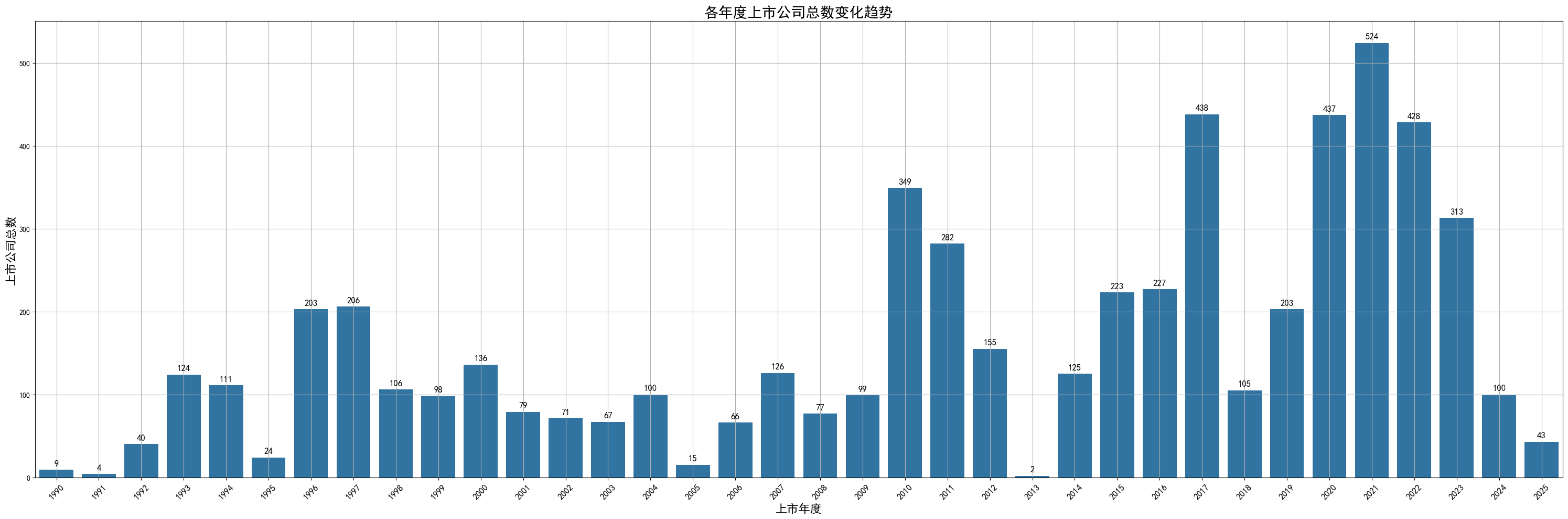
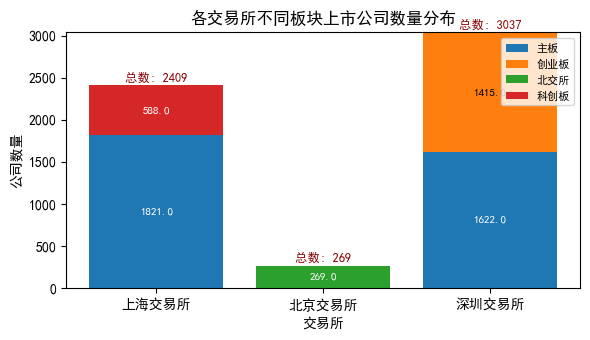
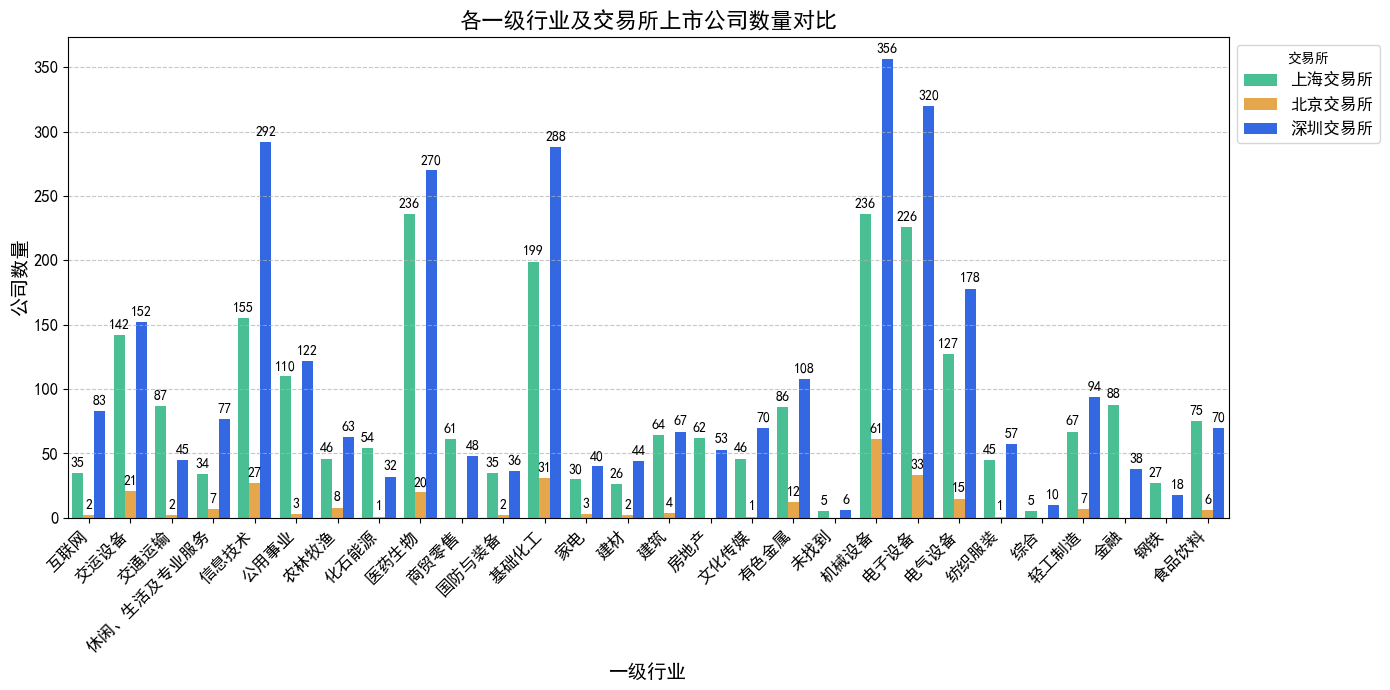
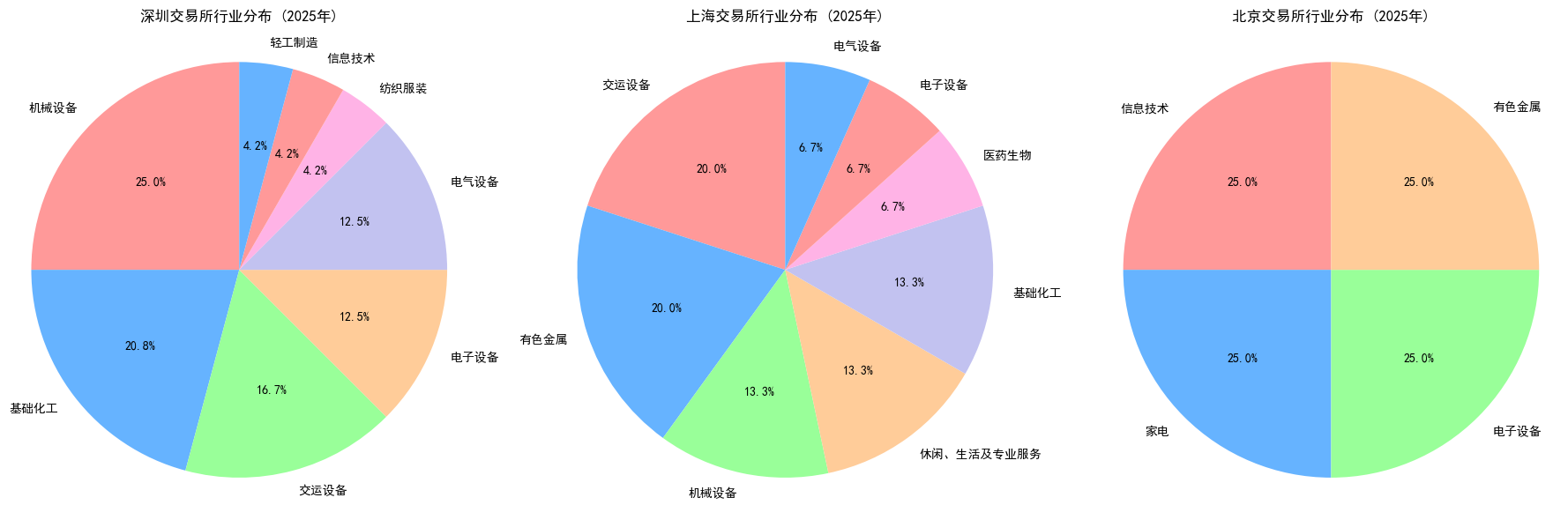
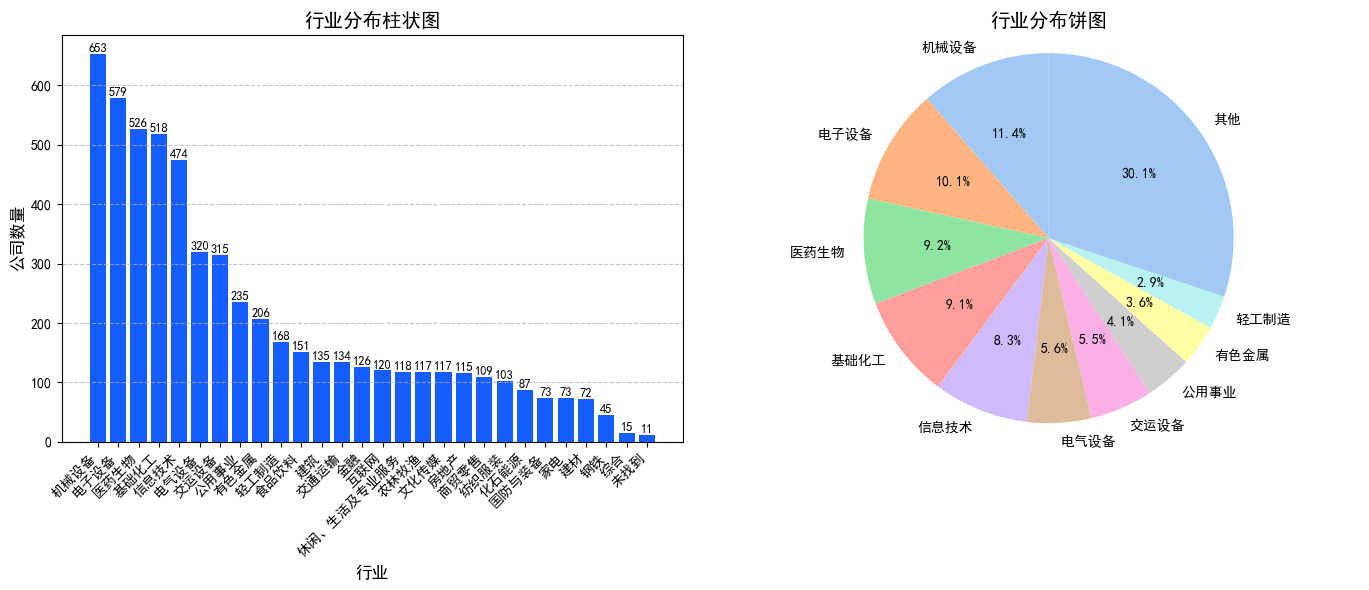
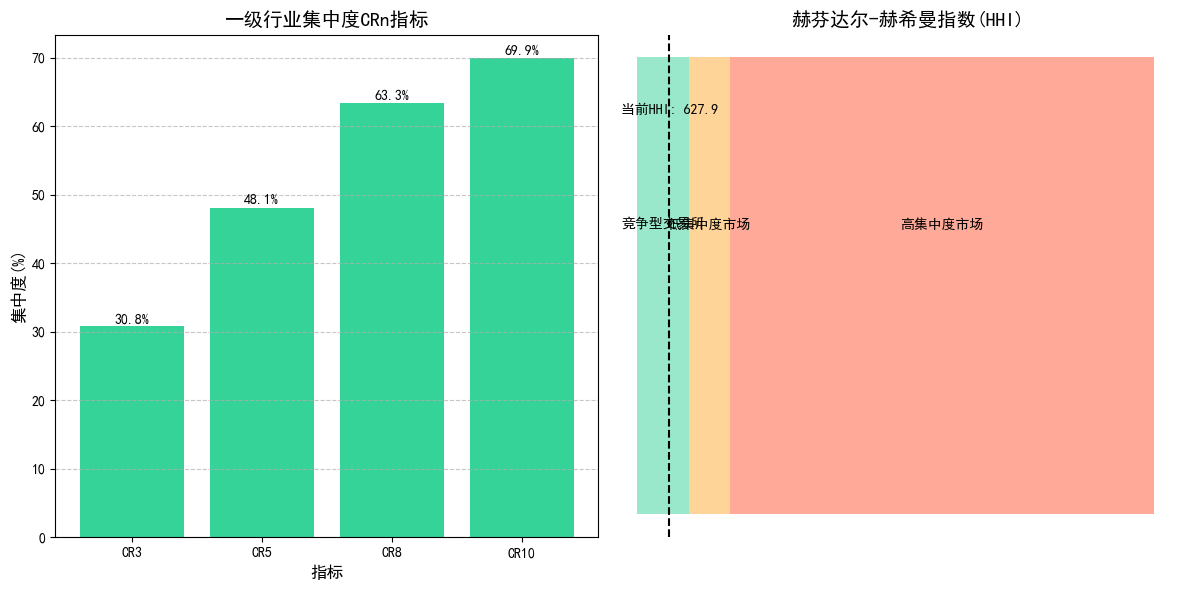
# 统计行业分布(使用“一级行业”字段)
industry_counts = df['一级行业'].value_counts().reset_index()
industry_counts.columns = ['一级行业', '公司数量']
# 计算行业总数
total = industry_counts['公司数量'].sum()
# 计算行业集中度指标(CRn)
def calculate_crn(data, n):
"""计算前n个行业的集中度"""
top_n = data.head(n)
return top_n['公司数量'].sum() / data['公司数量'].sum() * 100
# 计算不同n值的CRn
cr_values = {f'CR{i}': calculate_crn(industry_counts, i) for i in [3, 5, 8, 10]}
# 计算赫芬达尔-赫希曼指数(HHI)
hhi = ((industry_counts['公司数量'] / total) ** 2).sum() * 10000
# 创建画布
plt.figure(figsize=(12, 6))
# 绘制CRn指标图
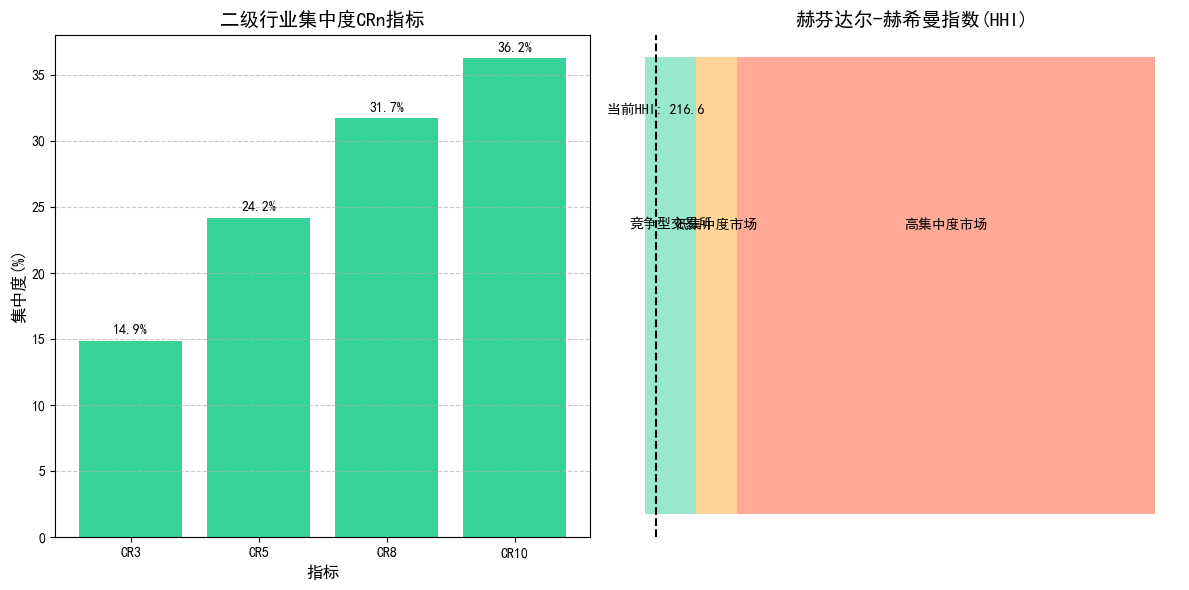
plt.subplot(1, 2, 1)
plt.bar(cr_values.keys(), cr_values.values(), color='#36D399')
plt.title('一级行业集中度CRn指标', fontsize=14)
plt.xlabel('指标', fontsize=12)
plt.ylabel('集中度(%)', fontsize=12)
plt.grid(axis='y', linestyle='--', alpha=0.7)
# 添加数据标签
for i, v in enumerate(cr_values.values()):
plt.text(i, v + 0.5, f'{v:.1f}%', ha='center', fontsize=10)
# 绘制HHI指标解读
plt.subplot(1, 2, 2)
plt.axis('off')
plt.title('赫芬达尔-赫希曼指数(HHI)', fontsize=14)
# HHI解读区间
hhi_levels = [
(0, 1000, '竞争型交易所', '#36D399'),
(1000, 1800, '低集中度市场', '#FFAA33'),
(1800, 10000, '高集中度市场', '#FF5733')
]
# 绘制解读区间
for level in hhi_levels:
plt.barh(0, level[1]-level[0], left=level[0], color=level[3], alpha=0.5)
plt.text(level[0]+(level[1]-level[0])/2, 0.1, level[2], ha='center', fontsize=10)
# 标记当前HHI值
plt.axvline(x=hhi, color='black', linestyle='--')
plt.text(hhi, 0.3, f'当前HHI: {hhi:.1f}', ha='center', fontsize=10)
plt.tight_layout()
plt.show()
# 打印集中度指标
print("一级行业集中度指标:")
print(f"CR3: {cr_values['CR3']:.1f}%")
print(f"CR5: {cr_values['CR5']:.1f}%")
print(f"CR8: {cr_values['CR8']:.1f}%")
print(f"CR10: {cr_values['CR10']:.1f}%")
print(f"HHI: {hhi:.1f}")