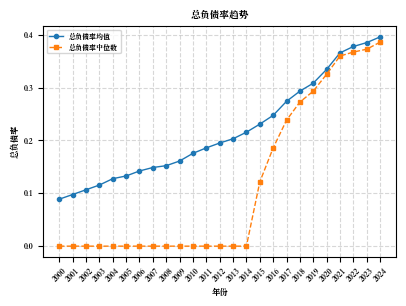
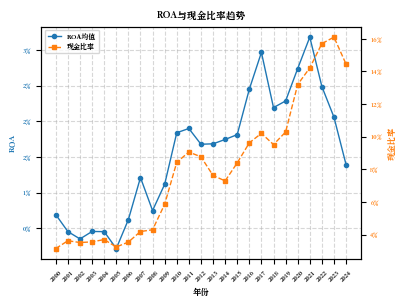
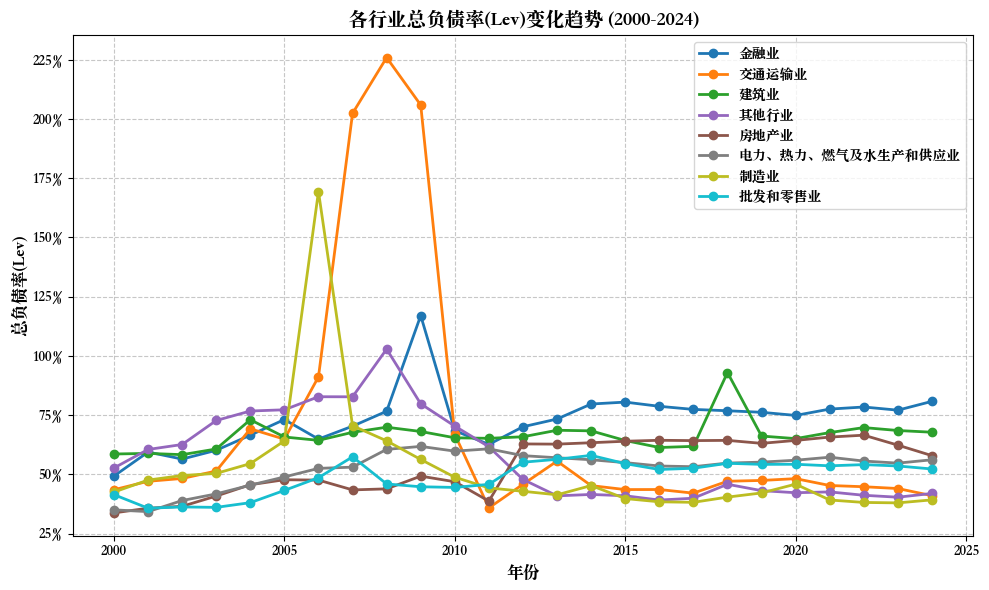
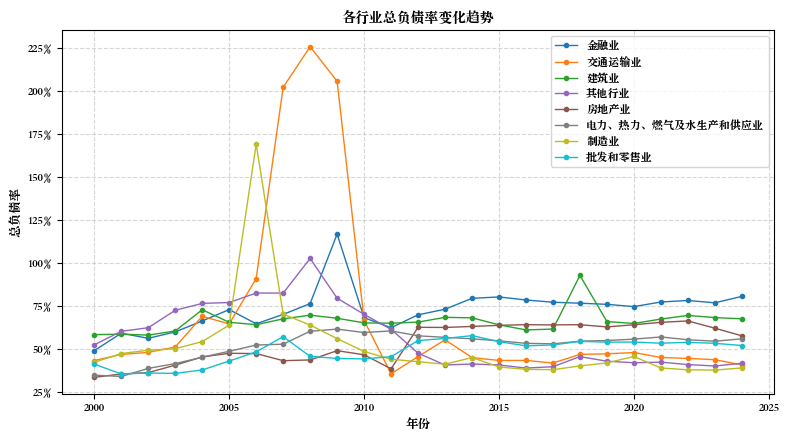
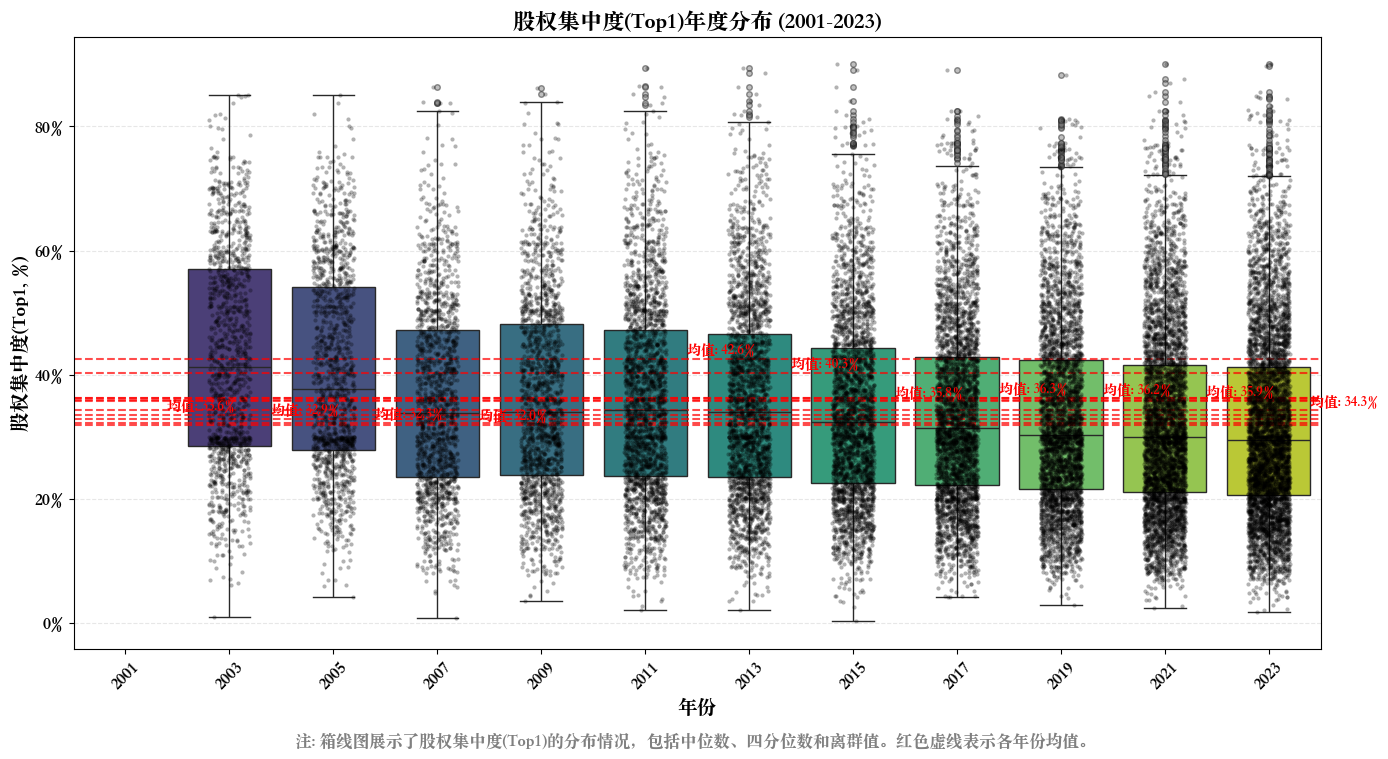
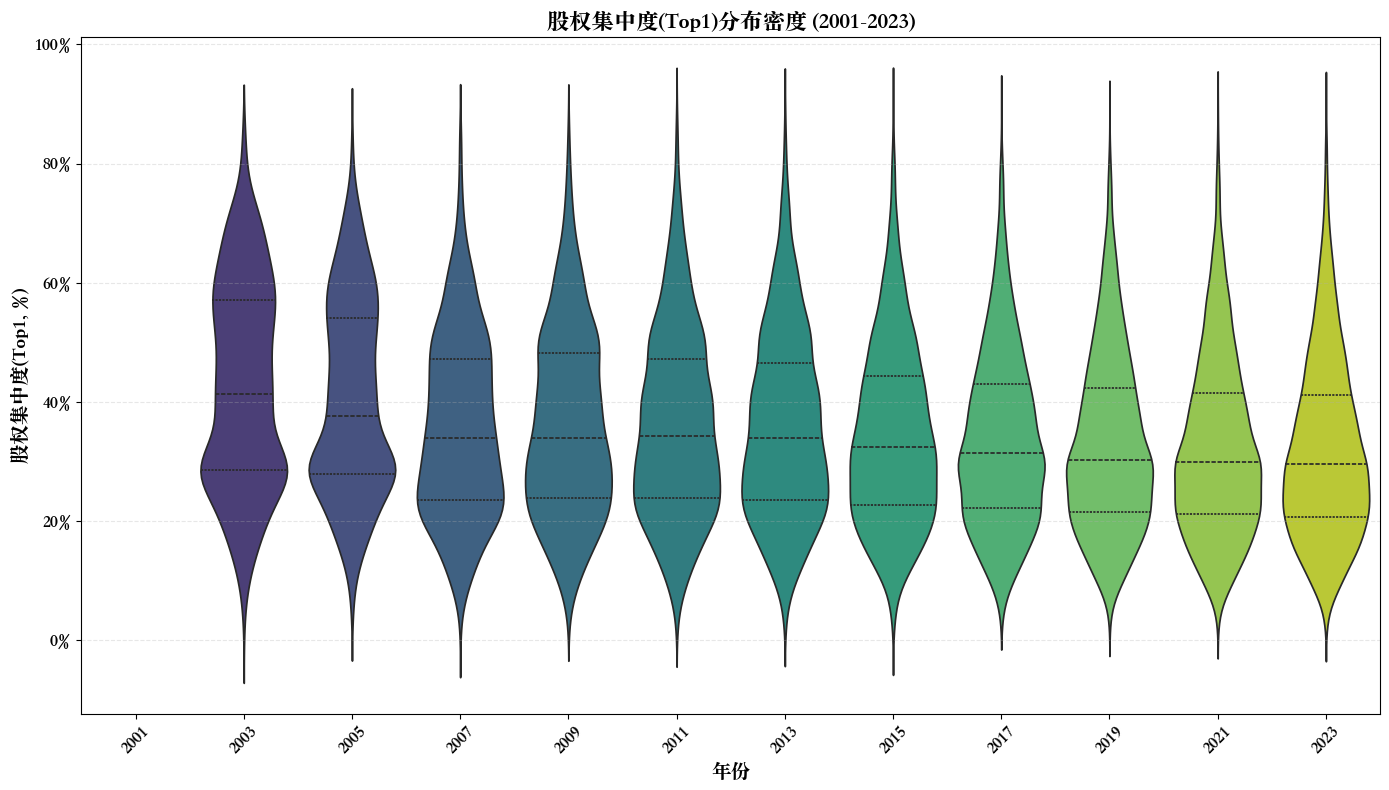
import pandas as pdimport numpy as npfrom openpyxl.styles import Border, Side, PatternFill, Fontfrom openpyxl.utils import get_column_letter# 1. 读取文件 = '/Users/wanshiqing/Desktop/python_code/merged_data.xlsx' print (f"正在读取文件: { input_path} " )= pd.read_excel(input_path)print (f"数据读取成功! 共 { len (df)} 行记录" )# 2. 计算并新增字段 print (" \n 计算并新增财务指标字段..." )def safe_divide(numerator, denominator):"""安全除法函数,处理分母为零的情况""" return np.where(denominator != 0 , numerator / denominator, np.nan)# 确保所需字段存在 = ['短期借款' , '长期借款' , '负债合计' , '资产总计' , '期末现金及现金等价物余额' , '净利润' , '所有者权益合计' ]for field in required_fields:if field not in df.columns:print (f"警告: 字段 ' { field} ' 不存在,尝试查找替代字段..." )= [col for col in df.columns if field in col or field.lower() in col.lower()]if possible_cols:= {possible_cols[0 ]: field}, inplace= True )print (f" 使用替代字段: { possible_cols[0 ]} 作为 { field} " )else :raise ValueError (f"无法找到必需的字段: { field} " )# 计算新增字段 'SLoan' ] = safe_divide(df['短期借款' ], df['资产总计' ])'LLoan' ] = safe_divide(df['长期借款' ], df['资产总计' ])'Lev' ] = safe_divide(df['负债合计' ], df['资产总计' ])'Cash' ] = safe_divide(df['期末现金及现金等价物余额' ], df['资产总计' ])'ROA' ] = safe_divide(df['净利润' ], df['资产总计' ])'ROE' ] = safe_divide(df['净利润' ], df['所有者权益合计' ])# 3. 创建行业字段 print (" \n 创建行业字段..." )= {'C' : '制造业' ,'D' : '电力、热力、燃气及水生产和供应业' ,'G' : '交通运输业' ,'E' : '建筑业' ,'K' : '房地产业' ,'F' : '批发和零售业' ,'J' : '金融业' # 确保行业代码字段存在 if '行业代码' not in df.columns:= [col for col in df.columns if '行业' in col or 'industry' in col.lower()]if possible_cols:print (f"使用替代字段作为行业代码: { possible_cols[0 ]} " )= possible_cols[0 ]else :raise ValueError ("无法找到行业代码字段" )else := '行业代码' # 将行业代码转换为字符串类型 = df[industry_col].astype(str )'行业首字母' ] = df[industry_col].str [0 ]'行业' ] = df['行业首字母' ].map (industry_mapping)# 处理无法映射的行业代码 = df[df['行业' ].isna()]['行业首字母' ].unique()if len (unknown_industries) > 0 :print (f"发现无法映射的行业代码: { unknown_industries} " )'行业' ] = df['行业' ].fillna('其他行业' )# 4. 按'行业'和'时间'分组,计算平均值 print (" \n 按行业和时间分组计算平均值..." )= df[df['时间' ] >= 2000 ]= df.groupby(['行业' , '时间' ]).agg({'SLoan' : 'mean' ,'LLoan' : 'mean' ,'Lev' : 'mean' ,'Cash' : 'mean' ,'ROA' : 'mean' ,'ROE' : 'mean' # 重命名列 = {'SLoan' : '短期借款比率' ,'LLoan' : '长期借款比率' ,'Lev' : '总负债率' ,'Cash' : '现金比率' ,'ROA' : '资产收益率' ,'ROE' : '净资产收益率' = True )# 按时间和行业排序 = grouped.sort_values(['时间' , '行业' ])# 5. 创建美观的实线表格 print (" \n 创建美观的实线表格..." )# 定义样式函数 def format_table(styler):# 设置百分比格式 format ({'短期借款比率' : ' {:.2%} ' ,'长期借款比率' : ' {:.2%} ' ,'总负债率' : ' {:.2%} ' ,'现金比率' : ' {:.2%} ' ,'资产收益率' : ' {:.2%} ' ,'净资产收益率' : ' {:.2%} ' # 设置表头样式 'selector' : 'th' , 'props' : ['border' , '1px solid black' ),'background-color' , '#4F81BD' ),'color' , 'white' ),'font-weight' , 'bold' ),'text-align' , 'center' )'selector' : 'td' , 'props' : ['border' , '1px solid black' ),'text-align' , 'center' )'selector' : 'tr:nth-child(even)' , 'props' : ['background-color' , '#DCE6F1' )'selector' : 'tr:nth-child(odd)' , 'props' : ['background-color' , 'white' )# 设置列宽 ** {'width' : '100px' ,'max-width' : '100px' return styler# 应用样式 = grouped.style.pipe(format_table)# 保存为HTML = '/Users/wanshiqing/Desktop/industry_financial_metrics.html' with open (html_output_path, 'w' ) as f:print (f"HTML表格已保存至: { html_output_path} " )# 保存为带格式的Excel def apply_excel_formatting(writer, df, sheet_name= 'Sheet1' ):"""应用Excel格式设置""" = writer.book= writer.sheets[sheet_name]# 定义边框样式 = Border(= Side(style= 'thin' ),= Side(style= 'thin' ),= Side(style= 'thin' ),= Side(style= 'thin' )# 定义填充颜色 = PatternFill(start_color= '4F81BD' , end_color= '4F81BD' , fill_type= 'solid' )= PatternFill(start_color= 'DCE6F1' , end_color= 'DCE6F1' , fill_type= 'solid' )= PatternFill(start_color= 'FFFFFF' , end_color= 'FFFFFF' , fill_type= 'solid' )# 定义字体 = Font(color= 'FFFFFF' , bold= True )= Font()# 设置列宽 for i, col in enumerate (df.columns):= get_column_letter(i + 1 )= 15 # 应用格式到所有单元格 for row in range (0 , len (df) + 1 ):for col in range (0 , len (df.columns)):= worksheet.cell(row= row + 1 , column= col + 1 )= thin_border# 表头样式 if row == 0 := header_fill= header_font# 数据行样式 else :if row % 2 == 0 := even_row_fillelse := odd_row_fill= data_font# 冻结首行 = 'A2' # 保存为Excel = '/Users/wanshiqing/Desktop/industry_financial_metrics.xlsx' with pd.ExcelWriter(excel_output_path, engine= 'openpyxl' ) as writer:= False , sheet_name= '行业财务指标' )= '行业财务指标' )print (f"带格式的Excel表格已保存至: { excel_output_path} " )# 创建行业汇总表 = grouped.groupby('行业' ).agg({'短期借款比率' : 'mean' ,'长期借款比率' : 'mean' ,'总负债率' : 'mean' ,'现金比率' : 'mean' ,'资产收益率' : 'mean' ,'净资产收益率' : 'mean' # 应用样式到汇总表 = industry_summary.style.pipe(format_table)# 保存汇总表 = '/Users/wanshiqing/Desktop/industry_summary.html' with open (summary_html_path, 'w' ) as f:print (f"行业汇总HTML表格已保存至: { summary_html_path} " )# 保存汇总表到Excel = '/Users/wanshiqing/Desktop/industry_summary.xlsx' with pd.ExcelWriter(summary_excel_path, engine= 'openpyxl' ) as writer:= False , sheet_name= '行业汇总' )= '行业汇总' )print (f"行业汇总Excel表格已保存至: { summary_excel_path} " )# 保存处理后的完整数据 = '/Users/wanshiqing/Desktop/processed_financial_data.xlsx' = False )print (f"处理后的完整数据已保存至: { full_output_path} " )print (" \n 第七步处理完成!" )