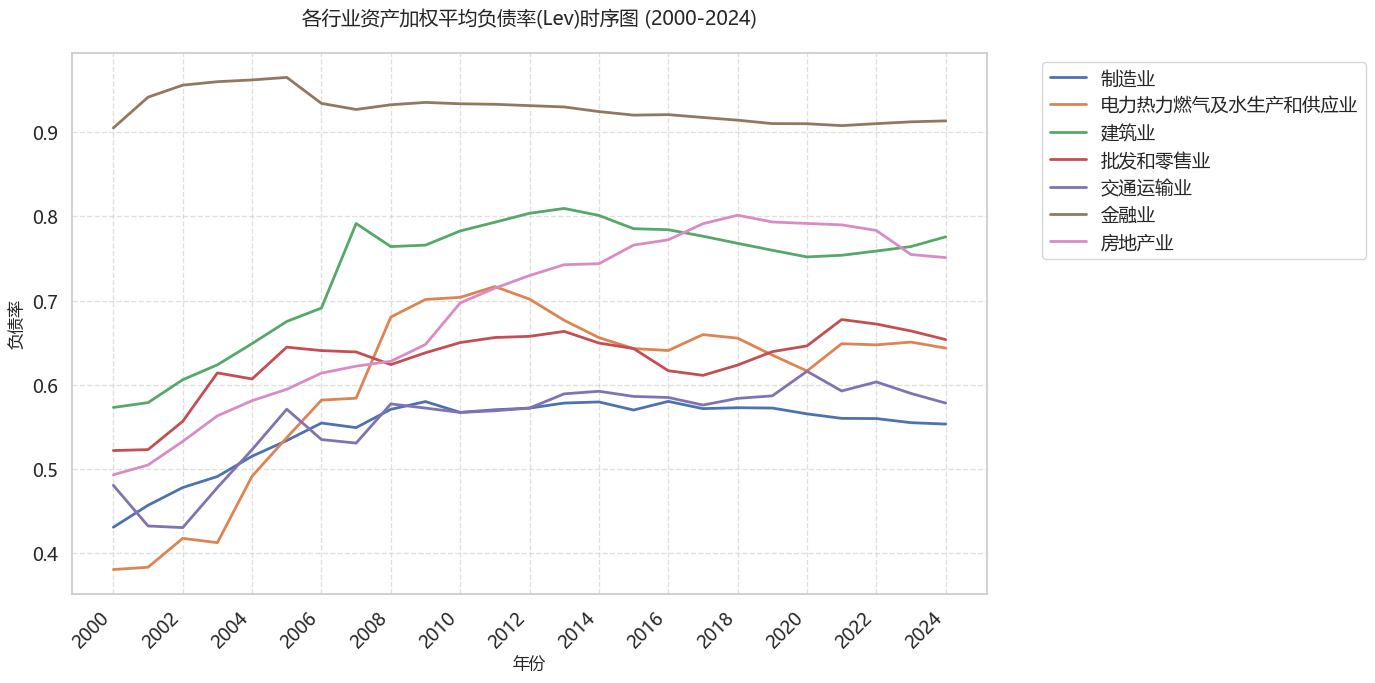
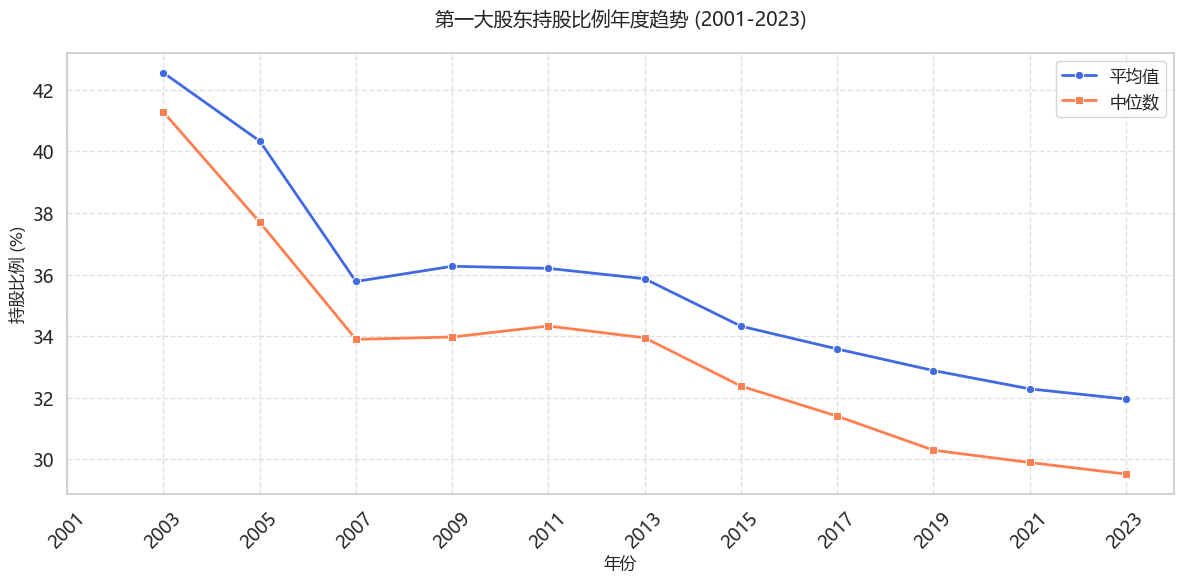
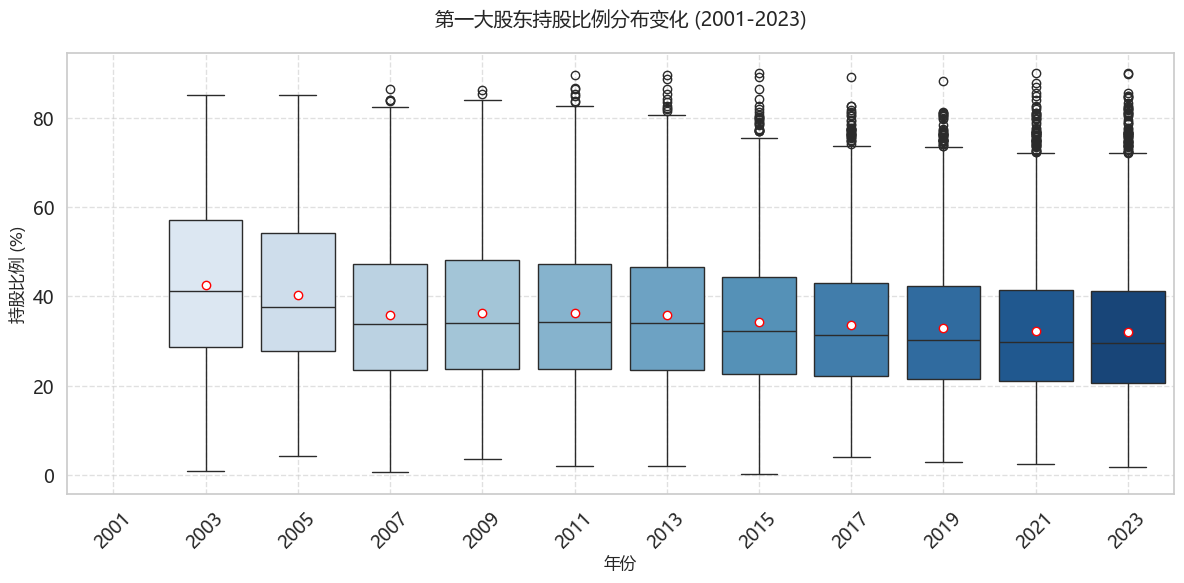
c:\Users\ASUS\anaconda3\envs\myenv312\Lib\site-packages\pandas\core\arraylike.py:399: RuntimeWarning: divide by zero encountered in log
result = getattr(ufunc, method)(*inputs, **kwargs)
C:\Users\ASUS\AppData\Local\Temp\ipykernel_20756\3875238943.py:51: DeprecationWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
weighted_mean = industry_data.groupby('时间').apply(
C:\Users\ASUS\AppData\Local\Temp\ipykernel_20756\3875238943.py:51: DeprecationWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
weighted_mean = industry_data.groupby('时间').apply(
C:\Users\ASUS\AppData\Local\Temp\ipykernel_20756\3875238943.py:51: DeprecationWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
weighted_mean = industry_data.groupby('时间').apply(
C:\Users\ASUS\AppData\Local\Temp\ipykernel_20756\3875238943.py:51: DeprecationWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
weighted_mean = industry_data.groupby('时间').apply(
C:\Users\ASUS\AppData\Local\Temp\ipykernel_20756\3875238943.py:51: DeprecationWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
weighted_mean = industry_data.groupby('时间').apply(
C:\Users\ASUS\AppData\Local\Temp\ipykernel_20756\3875238943.py:51: DeprecationWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
weighted_mean = industry_data.groupby('时间').apply(
C:\Users\ASUS\AppData\Local\Temp\ipykernel_20756\3875238943.py:51: DeprecationWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
weighted_mean = industry_data.groupby('时间').apply(
C:\Users\ASUS\AppData\Local\Temp\ipykernel_20756\787522106.py:63: FutureWarning:
Passing `palette` without assigning `hue` is deprecated and will be removed in v0.14.0. Assign the `x` variable to `hue` and set `legend=False` for the same effect.
sns.boxplot(